Hello, Hello!
This is my first Blog/Article or whatever it ends up being :)
It is heavily inspired by this amazing (must-watch) YouTube video by Andrej Karpathy: (https://youtu.be/7xTGNNLPyMI) [GOAT AI Simplifier]
Deep Dive into LLMs like ChatGPT
If you've ever wondered how these LLMs came into existence, this article will help you get an overview of how everything is built. You'll be surprised at how simple the foundation actually is!
So, few questions you might or might not had:
- What is ChatGPT, Claude, Gemini...?
- How do they know so much about everything?
- What are the prerequisites to creating an LLM?
- How did they advance so much in such a short period of time?
ChatGPT, Claude, Gemini... are all Large Language Models (LLMs).
An LLM is an AI that learned and trained on how to use patterns from lots and lots of text to understand your words and reply in a useful way.
To really understand how everything works, we are going to split the pipeline into stages, covering each stage step-by-step.
Pretraining Stage
Step 1: Download and preprocess the Internet
In this fist step, a very large dataset of text crawled from internet is collected, processed and stored.
To do this, AI companies generally have two options:
- Crawl the web themselves, like companies such as OpenAI or Anthropic among others do.
- Use a public repository of crawled webpages, like the one maintained by the non-profit CommonCrawl (which is exactly what the Fineweb dataset did).
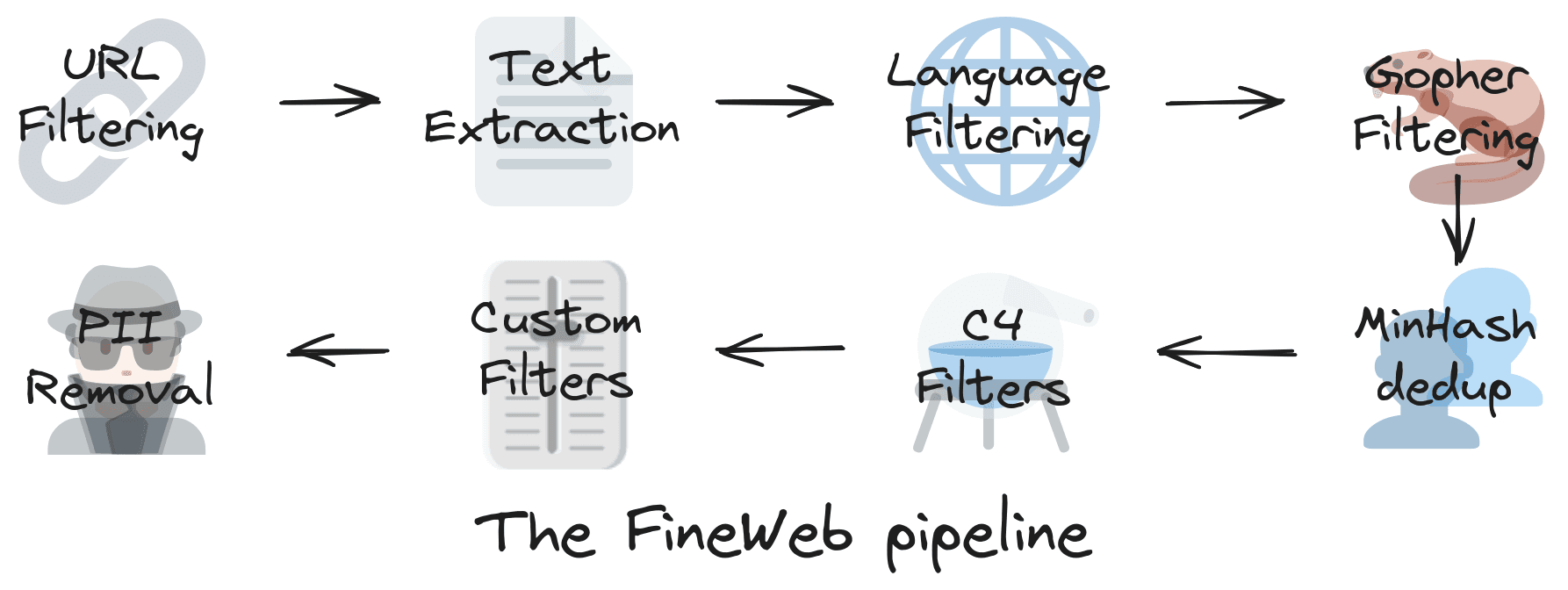
The collected dataset is then cleaned from deduplication, sensitive info (like social numbers, names...), blacklist content... .
Step 2: Tokenization
After the first step, we are left with a massive corpus of clean text that is ready to be used to train our model.
A quick look ahead:
The model we are going to train requires a finite, specific set of symbols to work with (letters, emojis, special characters, etc.).
At the same time, there is a strict hardware limit on how much data the model can process at once.
This makes the sequence length of our input a finite and precious resource.
So, in simple terms:
Tokenization is the set of rules that dictates how we break text down into smaller pieces so it can be efficiently fed to the model.
We all know that computers only work with raw bits (1s and 0s).
- -If we decided to feed the model with raw bits, the input would become extremely long and completely meaningless at a language level.
"cat" → 01100011 01100001 01110100That is 24 distinct symbols just to represent a simple three-letter word, all without giving the AI any true concept of letters or meaning.
- -If we step up to UTF-8 encoding: Bytes group bits into sets of 8 and are commonly used to represent characters.
"cat" → [99, 97, 116]This is much shorter than raw bits, but each byte still only represents a single character. The model would have to work incredibly hard just to learn how characters combine into words before it even gets to meaning.
- -Relying only on 255 character combinations would still result in a very long sequence length. So we want to shrink the sequence further in exchange for a larger overall vocabulary!
- -To do this, we use an algorithm called Byte Pair Encoding (BPE). This groups frequent patterns for consecutive bytes or symbols that occur very frequently together, and "mints" a brand new symbol with a unique ID to represent that pair.
- -GPT-4, for example, uses exactly 100,277 of these minted symbols (tokens).

Step 3: Neural Network Training
A neural network is a computer system inspired by how the brain learns by spotting patterns in what is sees. It’s made of simple connected units that pass information to each other! As it trains, it adjusts these connections to get better at tasks like recognizing images or understanding text...
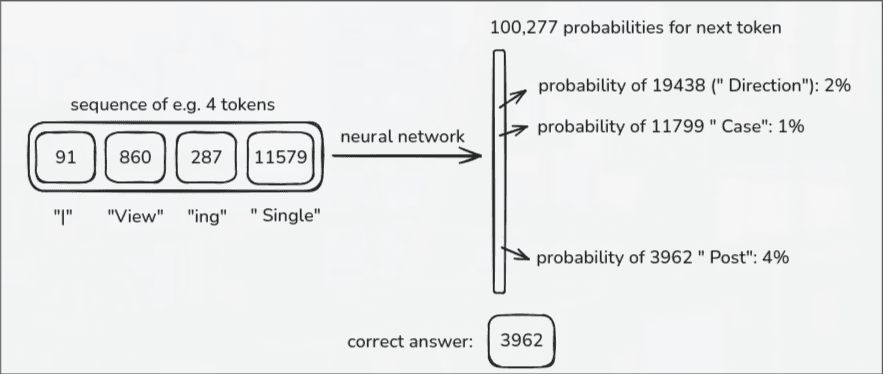
In the training phase, our text is tokenized by something like GPT-4's BPE, meaning any single token input corresponds to one of 100,277 combinations.
We pick a random sequence of tokens from our internet dataset. Let's say we grab a chunk of 8,000 tokens. We feed it into the Neural Network, and it spits out 100,277 probabilities with a percentage chance for every single possible token in its vocabulary predicting what the *next* token in the sequence should be.
Because we already have the original dataset, we know exactly what word *actually* comes next. So, we mathematically adjust the model's internal parameters to increase the probability of the correct token and lower the probability of the wrong ones. We iterate this millions of times until we reach a reasonably low "loss value" (meaning the model is highly accurate).

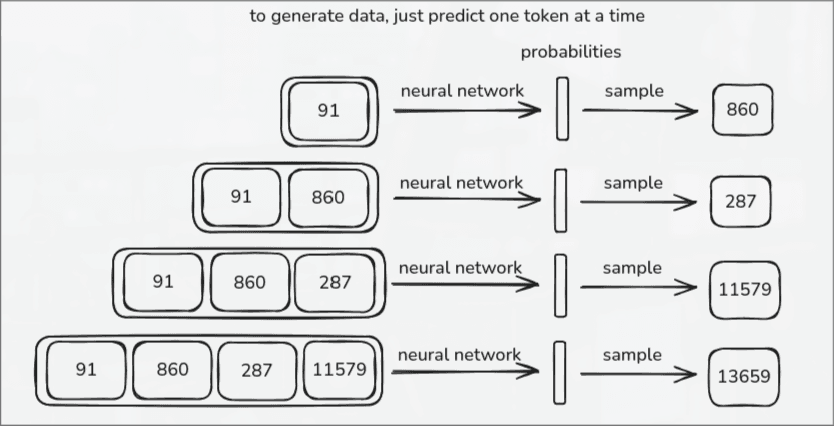
Step 4: Inference
Once the model is fully trained, the neurons now have "fixed" weights. Inference is the one taking action when you interact with the model. It predicts one token at a time to generate the response.
At the end of this massive Pretraining stage, we are left with a Base Model. However, a base model only completes the text you input into it. It doesn't know how to answer questions, format code, or act like an assistant!
Example: If you input "The capital of Morocco is."
It will try to continue with the most likely next words. Not because it "knows" geography, but purely because it has seen similar text millions of times before.
Some early famous base models:
- -OpenAI GPT-2 (2019): 1.6 billion parameters, trained on 100 billion tokens.
- -Llama 3 (2024): 405 billion parameters, trained on 15 trillion tokens.
When we say OpenAI's GPT-2 has 1.6 billion parameters, it essentially means the model has 1.6 billion "memory slots" or connections. The 100 billion tokens simply represents the total amount of text the model read during training.
But! if base models just complete text, how do we get ChatGPT?
That is exactly why we need the final step: Fine-tuning and Instruction Training. This is what turns a raw text completion machine into something that feels like a helpful assistant!
Fine-Tuning
To finally get an assistant that can answer questions and interact with users, we create a high quality dataset of actual conversations (Q&A formats, instructional tasks...).

These conversational datasets are created either by hiring real human labelers to write out perfect interactions, or by using another powerful LLM to generate them!
This is why chatting with a model feels like you are interacting with a real persona. The model is specifically fine-tuned on a structured format that closely imitates human conversation.
After creating the conversations dataset, we then replace the Internet data collected in the very first time with this dataset and continue training the model from where we left off, until we finally achieve a state that is assisting and performing.
...